
この記事ではPythonでスクレイピングしたデータをMySQLデータベースにインポートする方法を解説しています。
Pythonウェブスクレイピングの基本についてはこちらの記事を参照ください。
以下では CSVファイルからデータをMySQLにインポートする方法と、ウェブサイトから直接インポートする方法を説明します。例えばスクレイピングした商品サイトの各商品情報をMySQLにインポートすることで、そのデータをFlaskなどで利用できます。
CSVファイルからデータをMySQLにインポートする
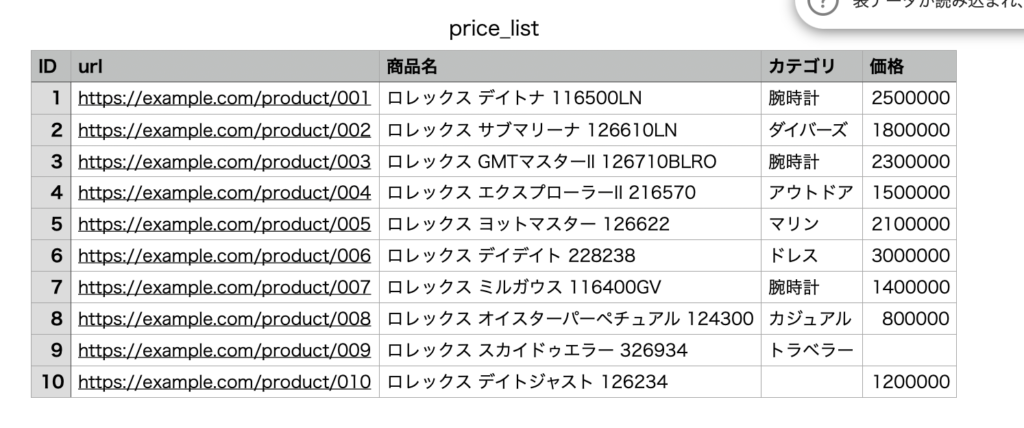
ここでは、サンプルファイルであるprice_list.csvをMySQLにインポートします。商品サイトをスクレイピングし、商品URL、商品タイトル、カテゴリ、そして価格を取得しています。このようにスクレイピングしたデータをCSVに保存する方法についてはこちらの記事を参照ください。
以下のコードでは指定したテーブルが既に存在する場合、インポート処理をしないようにしています。データを上書きしたい場合、新しいデータのみ更新したい場合などあるかと思うので、好みで調整してください。上書きするように設定すれば、勿論元のデータは消えてしまうので注意してください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 |
import pandas as pd import numpy as np from sqlalchemy import create_engine, MetaData, Table, Column, String, Float from sqlalchemy.orm import sessionmaker from sqlalchemy import inspect # MySQL接続情報 user = 'your_username' # MySQLのユーザー名 password = 'your_password' # MySQLのパスワード host = 'your_host' # ホスト名 database = 'your_database' # データベース名 # データベースの接続情報を設定 connection_string = f'mysql+pymysql://{user}:{password}@{host}:3306/{database}' engine = create_engine(connection_string) Session = sessionmaker(bind=engine) # CSVファイルのパス file_path = '/path/to/your/price_list.csv' # 実際のファイルパスに置き換えてください # CSVファイルからデータを読み込む df = pd.read_csv(file_path, dtype=str) # 新しいデータフレームを作成 new_df = pd.DataFrame() new_df['url'] = df['url'] new_df['product_name'] = df['商品名'] new_df['category'] = df['カテゴリ'] new_df['price'] = df['価格'].astype(float) # 価格を浮動小数点数に変換 # テーブル名を変数に格納 table_name = 'price_list' # テーブルのメタデータと定義 metadata = MetaData() price_list_table = Table(table_name, metadata, Column('url', String(255), primary_key=True), # URLは主キー Column('product_name', String(255), default=None), # 商品名 Column('category', String(255), default=None), # カテゴリ Column('price', Float, default=None), # 価格は数値 mysql_charset='utf8mb4', mysql_collate='utf8mb4_general_ci' ) # セッションを開始 session = Session() # テーブルが存在する場合、処理を終了 if inspect(engine).has_table(table_name): print("Table already exists. Skipping data insertion.") session.close() # セッションを閉じる else: # テーブルが存在しない場合のみ作成 metadata.create_all(engine) print("Table created.") # NaNをNoneに置き換える new_df.replace({np.nan: None}, inplace=True) # データを辞書形式に変換 data_to_insert = new_df.to_dict(orient='records') # データを挿入してコミット session.execute(price_list_table.insert(), data_to_insert) session.commit() # セッションを閉じる session.close() # 挿入したデータの件数を表示 print(f'Inserted {len(new_df)} records into the database.') |
このコードブロックは、CSVファイルからデータを読み込みMySQLデータベースに挿入するプロセスを実装しています。以下は各ステップの説明です。
ライブラリのインポート
|
1 2 3 4 5 |
import pandas as pd import numpy as np from sqlalchemy import create_engine, MetaData, Table, Column, String, Float from sqlalchemy.orm import sessionmaker from sqlalchemy import inspect |
・pandas: CSVファイルの読み込みに使用します。
・numpy: データ操作、特に欠損値処理に使用します。
・sqlalchemy: データベース接続や操作、テーブルの作成、データの挿入などに使用します。
・sessionmaker: データベース操作のセッション管理に使用します。
・inspect: テーブルの存在確認に使用します。
データベース接続設定
|
1 2 3 4 5 6 7 8 9 10 11 |
# MySQL接続情報 user = 'your_username' # MySQLのユーザー名 password = 'your_password' # MySQLのパスワード host = 'your_host' # ホスト名 database = 'your_database' # データベース名 # データベースの接続情報を設定 connection_string = f'mysql+pymysql://{user}:{password}@{host}:3306/{database}' engine = create_engine(connection_string) Session = sessionmaker(bind=engine) |
・データベース接続に必要な情報(ユーザー名、パスワード、ホスト、データベース名)を設定し、SQLAlchemyのcreate_engineを使ってデータベース接続エンジンを作成します。
・Sessionは、データベースとのやり取りを行うためのセッションを作成するために使用されます。
CSVファイルの読み込み
|
1 2 3 4 5 |
# CSVファイルのパス file_path = '/path/to/your/price_list.csv' # 実際のファイルパスに置き換えてください # CSVファイルからデータを読み込む df = pd.read_csv(file_path, dtype=str) |
データフレームの作成
|
1 2 3 4 5 6 |
# 新しいデータフレームを作成 new_df = pd.DataFrame() new_df['url'] = df['url'] new_df['product_name'] = df['商品名'] new_df['category'] = df['カテゴリ'] new_df['price'] = df['価格'].astype(float) # 価格を浮動小数点数に変換 |
・新しいデータフレームnew_dfを作成し、CSVデータの特定の列(url, 商品名, カテゴリ, 価格)をコピーしています。
・価格(価格)の列は、文字列から浮動小数点数型に変換しています。
新しいデータフレームを作ることで、データの型を変換したり、不要な文字列を削除するなどインポート前に内容を整形することができます。
テーブルの定義
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# テーブル名を変数に格納 table_name = 'price_list' # テーブルのメタデータと定義 metadata = MetaData() price_list_table = Table(table_name, metadata, Column('url', String(255), primary_key=True), # URLは主キー Column('product_name', String(255), default=None), # 商品名 Column('category', String(255), default=None), # カテゴリ Column('price', Float, default=None), # 価格は数値 mysql_charset='utf8mb4', mysql_collate='utf8mb4_general_ci' ) |
・Tableを使って、price_listという名前のテーブルを定義しています。
・url列は文字列型で、主キーとして設定されており、product_name, category, priceも列として定義されています。
・文字セットと照合順序としてutf8mb4を指定し、日本語や絵文字などを扱えるようにしています。
ここでテーブルを定義しています。ここではURLを主キーとして設定し、その他カラムごとの型を設定しています。
セッションの開始とテーブルの存在確認
|
1 2 3 4 5 6 7 8 |
# セッションを開始 session = Session() # テーブルが存在する場合、処理を終了 if inspect(engine).has_table(table_name): print("Table already exists. Skipping data insertion.") session.close() # セッションを閉じる else: |
・セッションを開始し、テーブルが既に存在するかをinspectを使って確認します。存在する場合は処理を終了し、セッションを閉じます。
テーブル作成とデータ挿入
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# テーブルが存在しない場合のみ作成 metadata.create_all(engine) print("Table created.") # NaNをNoneに置き換える new_df.replace({np.nan: None}, inplace=True) # データを辞書形式に変換 data_to_insert = new_df.to_dict(orient='records') # データを挿入してコミット session.execute(price_list_table.insert(), data_to_insert) session.commit() # セッションを閉じる session.close() # 挿入したデータの件数を表示 print(f'Inserted {len(new_df)} records into the database.') |
・テーブルが存在しない場合は、新しいテーブルを作成します。
・new_df内の欠損値(NaN)をSQLに対応するNoneに置き換えています。
・データフレームを辞書形式に変換し、テーブルに挿入します。
・最後に、挿入したデータの件数を表示します。
price_list.csvファイルには空のデータが含まれており、MySQLにNullとしてインポートできるように設定しています。
ウェブサイトから直接MySQLにインポートする
CSVファイルからではなく、ウェブスクレイピングと同時にMySQLへインポートする方法です。ここでは既にテーブルが存在した場合でも処理が実行され、同じデータがある場合は上書きされるようにしています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 |
import requests from bs4 import BeautifulSoup from urllib.parse import urljoin from sqlalchemy import create_engine, MetaData, Table, Column, String from sqlalchemy.orm import sessionmaker from sqlalchemy.dialects.mysql import insert as mysql_insert # MySQL接続情報 user = 'your_username' # MySQLのユーザー名 password = 'your_password' # MySQLのパスワード host = 'your_host' # ホスト名 database = 'your_database' # データベース名 # データベースの接続情報を設定 connection_string = f'mysql+pymysql://{user}:{password}@{host}:3306/{database}' engine = create_engine(connection_string) Session = sessionmaker(bind=engine) # テーブル名を変数に格納 table_name = 'articles' # テーブルのメタデータと定義 metadata = MetaData() articles_table = Table(table_name, metadata, Column('url', String(255), primary_key=True), # URL Column('article_title', String(255), default=None), # 記事タイトル mysql_charset='utf8mb4', mysql_collate='utf8mb4_general_ci' ) # セッションを開始 session = Session() # テーブルを作成(存在する場合はそのまま) metadata.create_all(engine) print("Table exists or has been created.") # 指定ページから各リンクを見つける def find_links(): url = 'https://scraping-training.vercel.app/site?postCount=20&title=%E3%81%93%E3%82%8C%E3%81%AF{no}%E3%81%AE%E8%A8%98%E4%BA%8B%E3%81%A7%E3%81%99&dateFormat=YYYY-MM-DD&isTime=true&timeFormat=&isImage=true&interval=360&isAgo=true&countPerPage=0&page=1&robots=true&' webpage_response = requests.get(url) webpage_content = webpage_response.content webpage_soup = BeautifulSoup(webpage_content, "html.parser") base_url = 'https://scraping-training.vercel.app' links = [] a_tags = webpage_soup.select(".post-link") if a_tags: for a_tag in a_tags: href = a_tag.get('href') href = urljoin(base_url, href) title_div = a_tag.select_one(".post-title").text.strip() # データを辞書に格納 data_dict = {"url": href, "article_title": title_div} links.append(data_dict) # SQLに挿入(重複時に上書き) insert_stmt = mysql_insert(articles_table).values(data_dict) on_duplicate_key_stmt = insert_stmt.on_duplicate_key_update( article_title=insert_stmt.inserted.article_title ) # INSERT処理と重複時のUPDATE処理 session.execute(on_duplicate_key_stmt) print(f"Inserted/Updated article: {title_div}") return links # リンクを取得してデータを挿入 links_data = find_links() # コミットしてセッションを閉じる session.commit() session.close() # 挿入したデータの件数を表示 print(f'Inserted/Updated {len(links_data)} records into the database.') |
このコードブロックでは、特定のウェブページから記事情報を収集し、直接データベースに格納します。以下は各ステップの説明です。
ウェブページからリンクを取得
|
1 2 3 4 5 6 7 8 |
def find_links(): url = 'https://scraping-training.vercel.app/site?...' webpage_response = requests.get(url) webpage_content = webpage_response.content webpage_soup = BeautifulSoup(webpage_content, "html.parser") base_url = 'https://scraping-training.vercel.app' links = [] |
・requests.getで指定されたURLからウェブページの内容を取得し、BeautifulSoupで解析します。
・base_urlは相対URLを絶対URLに変換するために使用します。
・linksは、取得したリンク情報を格納するリストです。
記事リンクの抽出とデータベースへの挿入
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
a_tags = webpage_soup.select(".post-link") if a_tags: for a_tag in a_tags: href = a_tag.get('href') href = urljoin(base_url, href) title_div = a_tag.select_one(".post-title").text.strip() # データを辞書に格納 data_dict = {"url": href, "article_title": title_div} links.append(data_dict) # SQLに挿入(重複時に上書き) insert_stmt = mysql_insert(articles_table).values(data_dict) on_duplicate_key_stmt = insert_stmt.on_duplicate_key_update( article_title=insert_stmt.inserted.article_title ) # INSERT処理と重複時のUPDATE処理 session.execute(on_duplicate_key_stmt) print(f"Inserted/Updated article: {title_div}") |
・selectメソッドを使って、class=”post-link”の要素を取得します。
・各リンク(a_tag)からhrefを取得し、urljoinで絶対URLに変換します。
・タイトル(post-titleクラスの要素)を抽出し、テキストをきれいに整形します。
・data_dictとしてURLとタイトルを辞書形式で保存します。
・mysql_insertを使用し、データをテーブルに挿入します。重複があった場合(urlが既に存在する場合)は、タイトルを上書き更新するように設定しています。
データの挿入とセッションの終了
|
1 2 3 4 5 6 7 8 9 |
# リンクを取得してデータを挿入 links_data = find_links() # コミットしてセッションを閉じる session.commit() session.close() # 挿入したデータの件数を表示 print(f'Inserted/Updated {len(links_data)} records into the database.') |
・find_links関数を実行し、リンクデータを取得してデータベースに挿入します。
・すべての挿入が完了したら、session.commitでトランザクションをコミットし、セッションを閉じます。
・最後に、挿入または更新したレコードの件数を出力します。
まとめ
この記事では、Pythonを用いてCSVファイルからデータをMySQLデータベースにインポートする方法、ウェブサイトから直接MySQLにインポートする方法を解説しました。
スクレイピングしたデータをMySQLにインポートしておくことで、Flaskなどで利用しやすくなります。


